AWS reInvent 2020 Week1 Overview
December 6th, 2020
It's that time of the year where Amazon hosts its annual reInvent which is a free 3-week virtual conference.
If you haven't watched any of the talks yet, I highly recommend registering which I assume you can still do.
A decent number of talks happens in the morning or later in the evening, so if you have to work during the day, you can still catch some of the sessions.
While my main interest is in ML, I also watched several talks on databases like DynamoDB and serverless architecture. Here are my key takeaways.
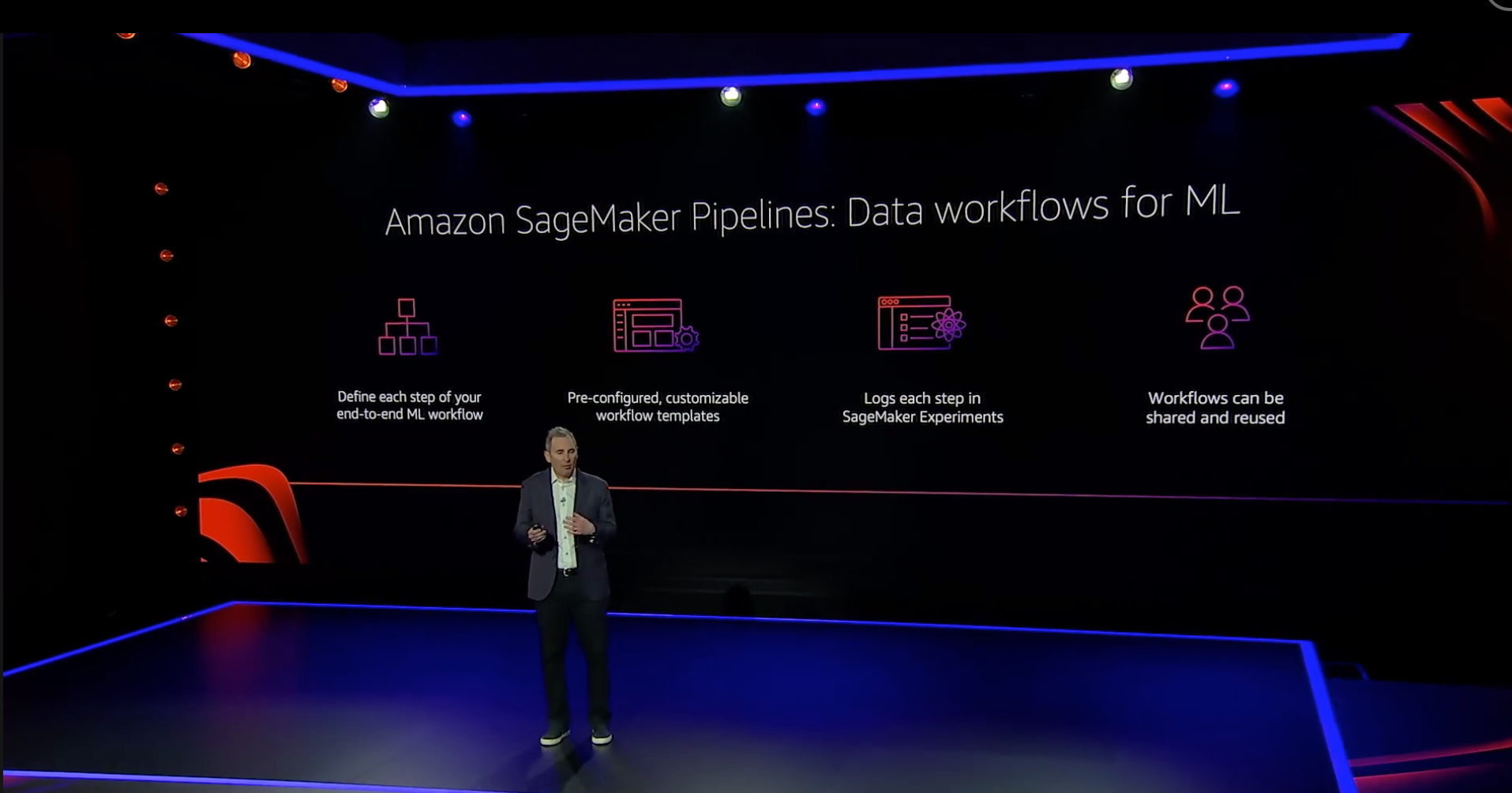
SageMaker
First introduced at reInvent 2017, SageMaker has become a popular Data Science tool. It allows you to not only train models in Python or R, but most importantly deploy them with just one line of code.
The sessions that I attended are (smiley faces represent how much I liked them):
- How to use fully managed Jupyter notebooks in AWS SageMaker
- Implementing MLOps practices with Amazon SageMaker
- Compliant and Secure ML
- Productionalizing R workloads using SageMaker featuring Siemens
What I really liked about these talks is that they emphasized the importance of model deployment which is commonly overlooked by data scientists. It also made me think more about setting up a secure ML environment to ensure that no training, real life data or models can be accessed without authorization. And sure, this is something that's frequently handled by network engineers or an IT department, but it doesn't mean that we shouldn't know what type of permissions we should have when working on ML projects and how to ensure that what we do is secure.
While Python may feel as a more suitable language when working with SageMaker, R is also fully supported. Your options are similar to the ones in Python. You can use RStudio with reticulate library, SageMaker notebook or AWS CLI.
Going back to the MLOps aspect, a lot of SageMaker talks also include AWS Step Functions architecture which seems to be a great combination for most ML projects.
AWS Step Functions
AWS Step Functions is a serverless function orchestrator that can be used to sequence AWS Lambdas and various AWS services. They are created using Amazon State Language which is JSON based.
You can perform a task with AWS Step Functions, execute branches in parallel (in addition to sequential calls), add conditional logic, add human intervention and error catching.
If you have an application that consists of calling multiple Lambdas or AWS services, you may want to seriously consider AWS Step Functions.
AWS has tons of resources on Step Functions which you can find Here.
DynamoDB
This was another talk that I really liked. I'm somewhat familiar with DynamoDB but after hearing this talk by Alex DeBrie made me realize that I've been under utilizing its capabilities.
Coming from a traditional SQL background, there is a steep learning curve and some of the concepts may even be mind blowing, such as lack of JOINs. I know, crazy stuff happening there!
However, you can't overlook advantages of DynamoDB such as speed especially for Software Development. Even in Data Science projects, if you work with JSON data a lot, DynamoDB is probably a far better alternative to relational databases.
Amazon Comprehend
McDonald's had an interesting talk on how they are utilizing AWS architecture to gain insights from customer surveys.
One of the services that McDonald's uses is Amazon Comprehend which allows them to perform various text analytics tasks, such as sentiment analysis, named entity recognition, keywords search on over 20M of open comments from their customer surveys.
McDonald's doesn't fully rely on Comprehend due to its limitations when it comes to domain-specific data. Their example "Fries were cold" was flagged as neutral sentiment, but AWS architecture allows to integrate NLP models built in-house to enhance accuracy.
While I can't say that these talks gave an in-depth overview of certain products or provided me with details on how to exactly acomplish certain tasks, they gave me enough examples of services that I should look into and their applications, which I think is the intent of these talks anyway.
I'm looking forward to more sessions in the next two weeks and will post my recap at the end of each week.
Feel free to leave your feedback on any other sessions that you found useful, or if you would like me to provide more recap on some of the sessions I mentioned above.